Gun Violence Research from NAP Report
My summary
This information comes from a report issued by the National Academies Press entitled "Priorities for Research to Reduce the Threat of Firearm-Related Violence", published in 2013. Contributors include the Institute of Medicine (IOM) and the National Research Council (NRC).
After reading the article, here are my initial thoughts about what parameters we should look at:
- Characteristics of violence
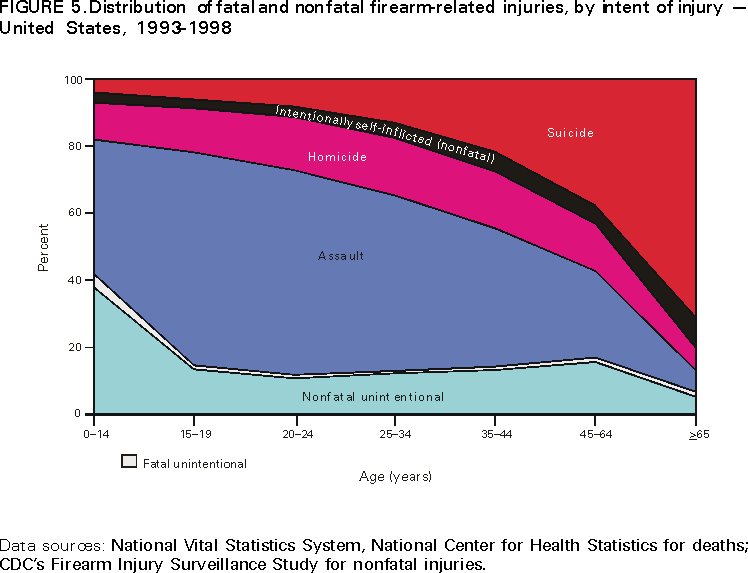
- Homicide, suicide, fatal, non-fatal, accidental
- Role of controlled substances
- Type of firearm / ammunition used
- Location
- Rural vs. Urban
- Type of location
- In a home, park, school, etc.
- General geographic information
- Victim / Perpetrator information
- Age, sex, race
- Relationship of victim to perpetrator
- History of mental illness and other risk factors
My Notes
***(I include these as a sort of summary of parts of the report I thought would be relevant to our study. Page numbers refer to the page of the PDF document I viewed)***
"Applying Public Health Strategies
to Reducing Firearm Violence" (p.29)
This section describes how
strategies can be implemented to prevent violence similar to those taken with
tobacco/alcohol and motor vehicles.
"Such strategies are designed
to interrupt the connection between three essential elements: the “agent” (the
source of injury [weapon or perpetrator]), the “host” (the injured person), and
the “environment” (the conditions under which the injury occurred)" (p.29)
1. Agent - The source of
injury
2. Host - The injured
person
3. Environment -
conditions under which injury occurred
There are 5 areas where more
information about gun violence is needed (p.33):
1. characteristics of
firearm violence,
2. risk and protective
factors,
3. interventions and
strategies,
4. gun technology, and
5. influence of video
games and other media.
[For the purposes of our
investigation, I suggest focusing on (1) and (2), which are discussed below.]
"Impact
of Existing Federal Restrictions on Firearm Violence Research" (p.34)
Information is lacking on:
1. Gun Sales, ownership,
possession
2. Names of gun
purchasers
"Policy
makers need a wide array of information,
including
community-level data and data concerning the circumstances of firearm deaths,
types of weapons used, victim–offender relationships, role of substance use,
and geographic location of injury — none of which is consistently
available" (p.35)
3. Circumstances of
death
4. Types of weapons used
5. Victim-offender
relationships
6. Role of substance use
7. Geographic
information
"Basic
information about gun possession, acquisition, and storage is
lacking"
(p. 36), [however I don't think this is the kind of information we will be able
to gather, so I won't write much about it]
"Data
about the sources of guns used in crimes are important because the means of
acquisition may reveal opportunities for prevention of firearm related
violence" (p.36)
Currently some information is
collected by the ATF
Only after a gun is used
in a crime, though, and does not track changes in ownership - not
representative of crimes
Possible
source of information: Weapon-Related Injury Surveillance System (WRISS) which
some municipalities use
CHARACTERISTICS
OF FIREARM VIOLENCE (p.37)
Basically, not much is known
To Look Into:
1. Types and number of
firearms that exist in the US
"In
general, there are three characteristics that define individual guns: gun type,
firing action, and ammunition" (p.39)
Types of Firearm Violence:
1. Broad level: fatal or
non-fatal
2. Fatal: homicides,
suicides, homicides, unintentional
a.
Mass-shootings sometimes another category
3. Non-fatal: unintentional
vs. intentional, threats, defensive use,
Though
there are cross classifying characteristics, such as age, sex, etc., these
categories are useful.
What
is known / not known about the following occurrences:
Suicide
Fairly well known:
Urban vs.
Rural
Age, Sex,
Race
Not well known:
Premeditated
or Impulsive?
Use of
firearm vs. other method
Homicide
Fairly Well known:
Victim-Offender
relationship (though still important)
Race,
Sex, age, etc.
Domestic
violence related shootings
Type of gun
used
In general, more is
known about homicides
Unintentional Fatalities
Fairly well known:
Self
inflicted?
Self
Defense?
Rural vs.
urban
Mass Shootings
Not well known:
Characteristics
of suicides associated with mass murders
Nonfatal
Fairly well known
Intentional
vs. unintentional
Self-inflicted
vs. other-inflicted
Use in
assault (as a threat)
SUMMARY
(p45):
Characterize
differences in nonfatal and fatal gun use across the
United
States. Examples of topics that could be examined:
1.What are the characteristics of
non-self-inflicted fatal and nonfatal gun injury?
o What attributes of
guns, ammunition, gun users, and other circumstances affect whether a gunshot
injury will be fatal or nonfatal?
o What characteristics
differentiate mass shootings that were prevented from those that were carried
out?
o What role do firearms
play in illicit drug markets?
2. What are the characteristics of
self-inflicted fatal and nonfatal gun injury?
o What factors (e.g.,
storage practices, time of acquisition) affect the decision to use a firearm to
inflict self-harm?
o To what degree can or
would prospective suicidal users of firearms substitute other methods of
suicide?
3. What factors drive trends in
firearm-related violence within subpopulations?
4. What factors could bring about a
decrease in unintentional firearm-related deaths?
Situational
factors associated with firearm violence (p.48)
1. Presence of drugs / alcohol
2. Intent: to acquire money, or as
an impulse
Need to protect personal
status/property
"Some
social and psychological research suggests that the need to defend social
status may increase the likelihood and severity of response to provocation in
the presence of an audience"(Griffiths et al., 2011; Papachristos, 2009)
(p.48)
3. Gang involvement
4. Other situational factors such as
excessive heat (Anderson et al., 1995), the presence of community disorder (or
“broken windows”)
5. Specific locations, e.g.:
house/apartment, public street, natural area, vehicle, parked car, athletic
area, hotels/motels, commercial areas
Study-proposed
research questions (p.50)
Three important research topics were
identified by the committee:
1) factors associated
with youth having access to, possessing, and carrying guns;
2) the impact of gun
storage techniques on suicide and unintentional injury, and
3) “high-risk”
geographic/physical locations for firearm violence.
Youth Gun Violence [probably can't
tackle most of these]
Examples of topics that
could be examined:
o Which
individual and/or situational factors influence the illegal acquisition,
carrying, and use of guns by juveniles?
o What types
of weapons do youths obtain and carry?
o How do
youths acquire these weapons, e.g., through legal or illegal means?
o What are
key community-level risk and protective factors(such as the role of social
norms), and how are these risk and protective factors affected by the social
environment and neighborhood/community context?
o What are
key differences between urban and rural youth with regard to risk and
protective factors for firearm-related violence?
IMPACT OF HAVING A FIREARM IN THE
HOME (p.52)
o What are the
associated probabilities of thwarting a crime versus committing suicide or
sustaining an injury while in possession of a firearm?
o What factors affect
this risk/benefit relationship of gun ownership and storage techniques?
o What is the impact of
gun storage methods on the incidence of gun violence—unintentional and
intentional—involving both youths and adults?
o What is the impact of
gun storage techniques on rates of suicide and unintentional injury?
PARTICULAR TYPES OF LOCATIONS (p.54)
1. What are the
characteristics of high- and low-risk physical locations?
2. Are the locations
stable or do they change?
3. What factors in the
physical and social environment characterize neighborhoods or sub-neighborhoods
with higher or lower levels of gun violence?
4. Which characteristics
strengthen the resilience of specific community locations?
5. What is the effect of
stress and trauma on community violence, especially firearm-related violence?
6. What is the effect of
concentrated disadvantage on community violence, especially firearm-related
violence?
QUESTIONS
WE PROBABLY WON'T BE ABLE TO GATHER DATA FOR:
More
information is needed on the effectiveness of intervention programs. Is this
something we'll be able to consider? (p. 61).
Possible factors: Childhood
education, poverty, substance use
More
information is needed about the effectiveness of gun safety technology